Clustered Database Guide
Introduction
Openfire uses a database to store most of the data that it needs to persist. Openfire can use both an embedded database and variety of external databases, as explained in the Database Installation Guide. For many applications, these options suffice. For others, where performance or resilience is of high importance, it can be desired to use a clustered database.
Most of the implementation details of configuring and using a clustered database server is specific to the vendor of your database. There is only a limited amount of generically available configuration in Openfire that is directly geared towards having a database cluster. This document will describe those, and will complement that with descriptions of generic approaches and best practices. You will need to cross-reference these with the clustering-related documentation of your database vendor.
This document describes approaches to have Openfire interact with a clustered database. The document is broken down in these sections:
Background
The term "database clustering" is somewhat ambiguous. The specific definition is often left to the interpretation of the vendor of your database product. Generally speaking, "database clustering" aims to improve one or more of the following characteristics:
- Reliability
- Minimize the impact of a single database server that becomes unavailable (e.g. software or hardware failure, scheduled maintenance).
- Scalability
- Improve the speed of database operations by spreading or targeting load
Replication Types
Replication is the manner in which database servers that make up a cluster synchronize data amongst themselves. There are a couple of commonly used approaches by database vendors to replicate data:
- active/active
- All database servers in the database cluster can equally read and write the data, exchanging data with each other to maintain state.
- active/passive
- Only one database server (the 'primary') is used for writing data, which replicates the data to the other, passive, servers ('secondaries') in the database cluster.
The 'active/active' replication type generally allows for a lot of flexibility: any server automatically replaces one if its siblings that becomes unavailable. However: creating a fully 'active/active' setup is often hard to accomplish. Sometimes, guarantees around data validity are different, or less strict.
Replication of the 'active/passive' type is typically easier to set up, and, as long as the authoritative server remains available, typically does not compromise on data validity constraints. However, this approach can be less fault-tolerant, especially when unexpected outages of the authoritative server occur. Depending on the vendor's functionality and the configuration, a secondary server may become the primary automatically, or may need manual "promotion".
Synchronous versus asynchronous replication
A common characteristic of an active/passive replication configuration is that the primary distributes data to the secondaries in an asynchronous, one-way manner. Unlike to synchronous replication (in which a commit that is performed on the primary typically blocks until all other cluster nodes have acknowledged that they have replicated the data), asynchronous replication typically makes no guarantees as to when certain data becomes available on secondary servers. Asynchronous secondaries can thus "lag behind": they do not offer any guarantee that a read will contain data that was just written to the primary server.
Some database vendors support replication types that offer a mix of these characteristics of asynchronous and synchronous replication. MySQL's semi-synchronous replication, for example, will cause a commit to the primary block until least one secondary server acknowledges the data.
When Openfire is configured to use a database cluster, it treats the database as a singular logical entity. After it applies a change to the database, it expects that change to be visible to subsequent transactions/queries, irrespectively of the Openfire cluster node that makes the database request, or the database server that processes the request. For this reason, Openfire, in its normal operation mode, should not interact with database servers that use an asynchronous replication type. Database servers that are populated through asynchronous replication should only be used for standby/backup purposes, or for custom, non-Openfire functionality that needs to use Openfire data (such as analytics and reporting).
Connecting Openfire to the database cluster
The Database Installation Guide describes how Openfire is configured to connect to a database. Primarily, a JDBC URL is used to define most of the configuration. This URL varies depending on your database vendor. These are some examples:
- MySQL
jdbc:mysql://HOSTNAME:3306/DATABASENAME- Microsoft SQL Server
jdbc:sqlserver://HOSTNAME:1433;databaseName=DATABASENAME;applicationName=Openfire- PostgreSQL
jdbc:postgresql://HOSTNAME:5432/DATABASENAME
Many (but not all!) solutions for database clustering involve exposing the database cluster on more than one database server address. Often, each database server in the cluster is uniquely addressable. Many database vendors allow you to supply more than one server address in the JDBC URL.
As shown above, JDBC URLs for non-clustered database connections differ greatly depending on the database vendor. The addition of cluster-specific configuration such as the definition of multiple hosts, or the desired replication type, adds even more variation. When you want to define the JDBC URL that is used to configure Openfire for database clustering, you will need to refer to the vendor-provided documentation. Some example JDBC URLs that define more than one database server, as well as additional configuration:
- MySQL
jdbc:mysql://PRIMARYHOSTNAME:3306,SECONDARYHOST:3306/DATABASENAME?failOverReadOnly=false- Microsoft SQL Server
jdbc:sqlserver://HOSTNAME:1433;databaseName=DATABASENAME;applicationName=Openfire;multiSubnetFailover=true- PostgreSQL
jdbc:postgresql://PRIMARYHOSTNAME:5432,SECONDARYHOSTNAME:5432/DATABASENAME?targetServerType=primary
Links to vendor-specific documentation
Using a load balancer
When attempting to connect Openfire to a set of database servers, it can be beneficial to have an intermediary entity managing the connections from Openfire to the database servers. A traditional load balancer can offer benefits, while more specialized load balancers can offer even more features.
When using a load balancer, all Openfire servers connect not directly to the database servers, but to the load balancer instead. Based on its configuration, it will forward the connection to one of the available database servers. This has the advantage of not leaking/embedding the clustering configuration into Openfire.
Load balancing based on server availability
By using a traditional load balancer, a lot of flexibility can be introduced in the network design. A core concepts of most load balancers is failure detection, but many load balancers also allow the servers that they are servicing to be disabled, or put in a 'maintenance mode', where connections are gracefully drained.
Load balancing based on query type
In database clusters that are based on an active/active replication type, load balancing is relatively straight-forward, as all database servers are generally able to service any request. In clusters that use an active/passive replication type, data modifications ('writes'), can only be processed by the primary server. Data reads can typically be processed by all the secondary database servers, provided that replication is synchronous.
At the time of writing, Openfire's database API does not distinguish between "read" and "write" database queries that are executed: it does not explicitly allow for different database-configuration to be used when processing a query of either type (however this is subject to a change). When configuring Openfire to connect to only the primary database servers, the role of the secondary server is essentially that of being a passive backup, or possibly a hot-standby.
Certain load balancers, such as ProxySQL and MariaDB MaxScale are able to inspect queries and route writes to a primary server, while distributing reads to the secondary servers. Using such a solution allows for distribution of load related to the database queries.
Example setup: active/passive setup with PostgreSQL and repmgr
For illustrative purposes only. The architecture in this example is for informational and discussion purposes only. It does not intent to define a 'production-grade' solution.
The following documents an architecture in which a cluster of Openfire servers interact with a cluster of PostgreSQL database servers. repmgr is used to manage the replication within the database cluster. Automatic fail-over is realised by a combination of repmgr detecting outages and promoting a secondary server as the primary, and using a specific JDBC URL configuration in Openfire to prefer connecting to whichever is the primary server.
Characteristics
- Improved redundancy
- Data will be available in more than one database, allowing for more fault-tolerant disaster recovery.
- Unchanged scalability
- Similar to working with a non-clustered database, Openfire interacts with a singular database server. This configuration does not introduce significant additional database capacity or performance. The added overhead of running a database cluster is largely compensated by using asynchronous replication.
- Active/passive replication
- Openfire will interact with only one database server. That server replicates it state to another server, that is used as a hot-standby for automatic fail-over.
- Asynchronous replication
- Replication from the primary to secondary servers is asynchronous (although configurable). This improves the time taken for queries (particularly non-read queries) as their execution does not need to be delayed until secondary servers have acknowledged the change. The downside of this is that secondary servers can "lag behind" the primary, which introduces a risk of small data loss in a disaster recovery scenario.
- Automatic fail-over
- In case of scheduled or unscheduled outage of the primary database server, repmgr will promote the secondary database server. Although some database queries performed by Openfire can fail, it should continue to operate in all but the most exceptional cases.
- Split-brain protection
- When a database server that previously crashed becomes available again, Openfire should not attempt to
use that server again, as now, that server no longer is the primary server. To prevent Openfire from
using the first server defined in the JDBC URL, use the
targetServerTypeJDBC parameter with an appropriate value.
Database configuration
Full PostgreSQL cluster installation and configuration is beyond the scope of this document. For this example we're using a containerised cluster using PostreSQL + repmgr bundled by Bitnami (see Docker Hub). Here, two PostgreSQL servers are created and configured with Streaming Replication, launching the first server as the designated initial primary server.
Below is an example Docker Compose file describing the two container instances for the example environment.
This is not a production-ready example. For example, there are no volumes defined for data persistence,
no backups configured, no external heathchecks, and no attempt to secure traffic moving across the Docker
network. It describes the simplest configuration of two machines, creating users for operation (one each for
an administrator, for openfire and for repmgr to use), and configuring repmgr for each machine. Launch this
example by copying it to an empty folder, and running docker compose up -d in a terminal.
Openfire configuration
To install the Openfire servers, follow the Openfire Installation Guide as well as the documentation of the Hazelcast plugin for Openfire.
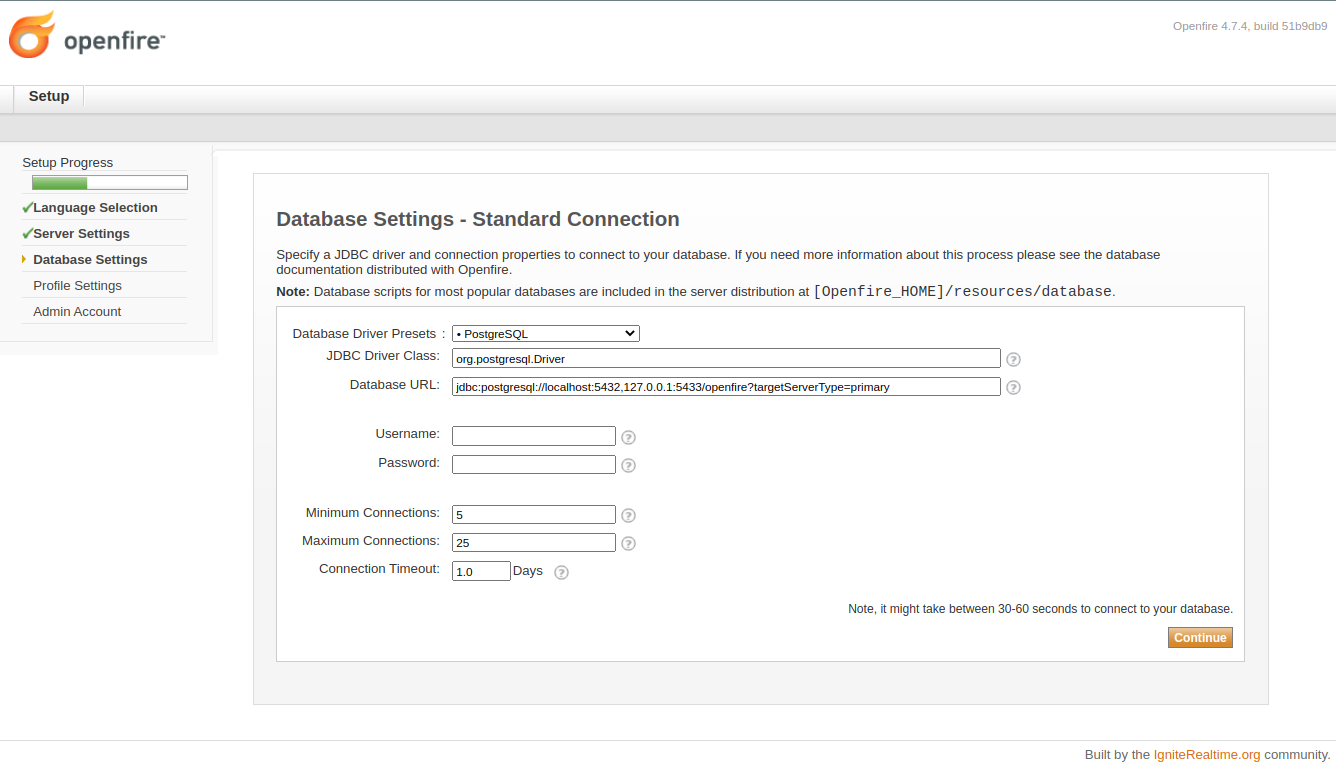
When configuring the database connection for Openfire, use a JDBC URL that defines the addresses for both
the primary and secondary database servers, as shown in the example below. The targetServerType
parameter (as documented in PostgreSQL's JDBC Driver
documentation) should be configured to instruct Openfire to connect to the database server marked as
'primary' by repmgr. Without this configuration, Openfire will attempt to connect to the server that is
configured first. This can lead to problems (eg: a split-brain scenario) when that server suffers from an
outage, after which it recovers (at which time it is unlikely to have a complete data set).
Given the above PostgreSQL docker setup, and the above JDBC example, assuming the containers are running on
the local machine, a correct JDBC connection string might look like this:
Alternatively, if configuring via autosetup in openfire.xml:
Note: If configuring the openfire.xml directly (e.g. for automatic provisioning of Openfire servers) the same settings are valid outside the autosetup tag.
With both servers initialised to talk to the database, move on to configuring Openfire Clustering, by installing the Hazelcast plugin and following the readme.

Once the Hazelcast plugin is installed, enable Openfire's clustering in Server > Server Manager > Clustering.
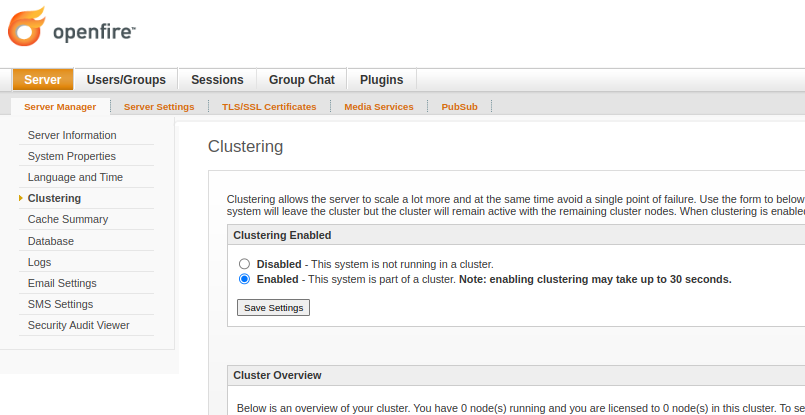
The networking configuration for Hazelcast is environment-sensitive. By default, it uses multicast, and may well work out-of-the-box. If not, the docs include instructions on how to override those defaults to suit your local network.
Once configured, you will have a pair of clustered Openfire servers, resilient to a single Openfire server failure, backed by a pair of clustered PostgreSQL servers, resilient to a single database server failure.
Automatic fail-over & recovery test
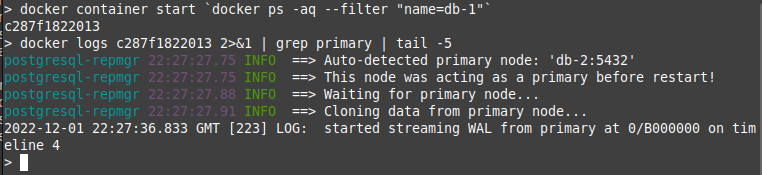
Given that we've got a containerised database environment, stopping and starting databases is easy to test. Run
docker container stop `docker ps -q --filter "name=db-1"` to stop the primary database server.
Continued use of the Admin console before and after this should continue without interruption. Checking logs
on the remaining database server should show the server being promoted to Primary.
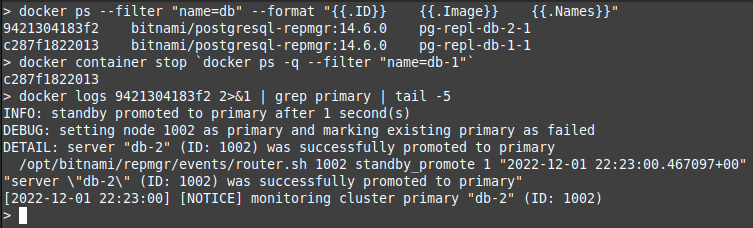
Restoring the first database server should see it connect to the second (now primary) server, and recover. At this point you can repeat the test for either server and see Openfire continue to operate without interruption.